Uber's strategy for a Bold Move to GCP ☁️
How Uber Leveraged GCP's IaaS to migrate Massive 1 Exabyte Data Stack
Hi, I'm Kamran Ali.
I have ~11.5 years of experience in Designing and Building Transactional / Analytical Systems.
I'm actually getting paid while pursuing my Hobby and its already been a decade.
In my next decade, I'm looking forward to guide and mentor engineers with experience and resources
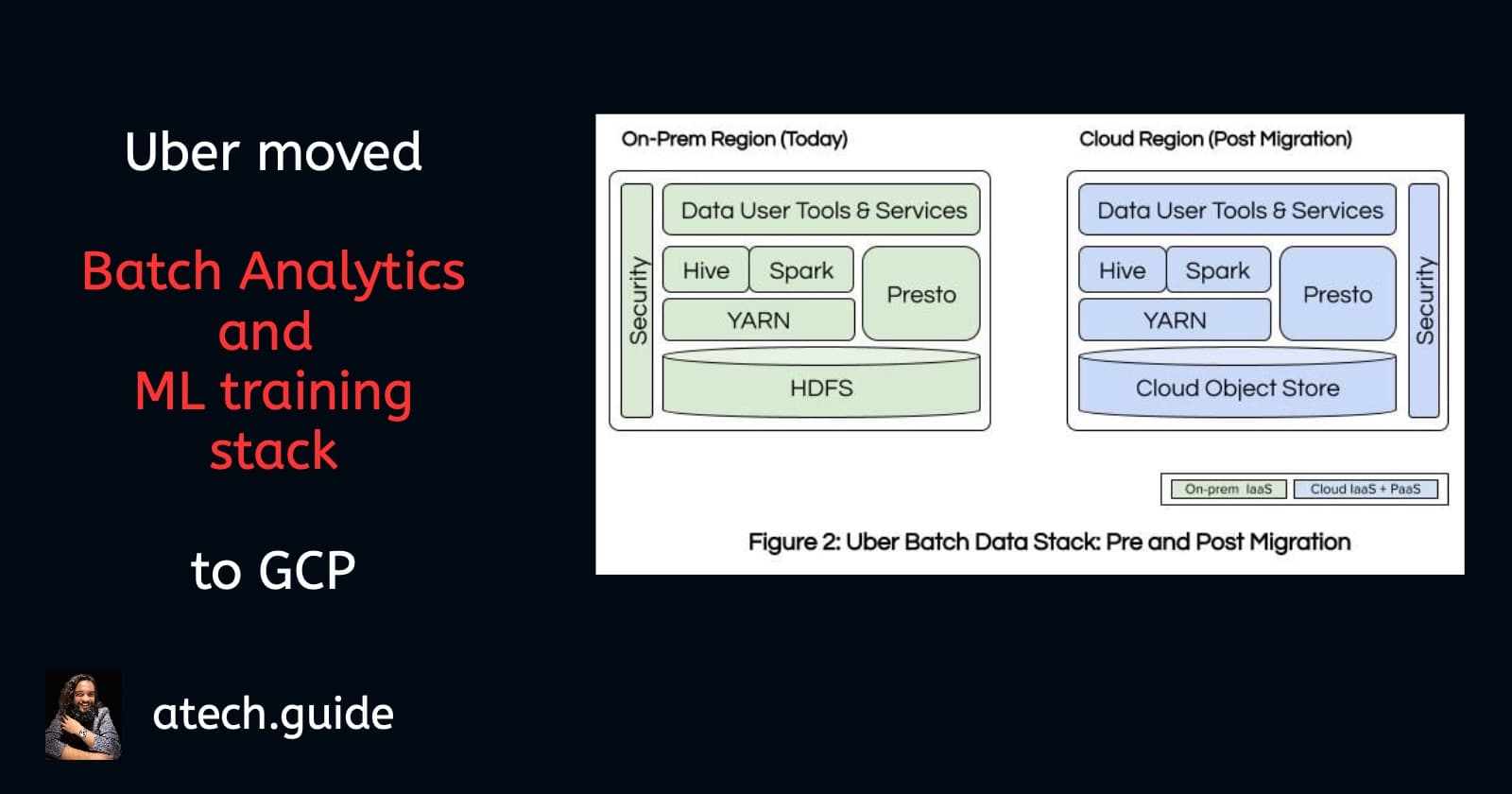
Uber's moved Batch Analytics and ML training stack to GCP
They hosts >1,000,000,000,000,000,000 byte of data across tens of thousands of servers. 🔥
Uber, managing a mind-boggling 1 exabyte of data, has strategically migrated its Batch Analytics and ML training stack to Google Cloud Platform (GCP).
Here's a breakdown of their strategy.
Key Decisions
Adopted GCP's object store for storage
Migrate the Data Stack to GCP's IaaS (Infrastructure as a Service)
This 'lift and shift' approach allowed for a rapid migration with minimal disruption, as they could replicate their existing setup on GCP's IaaS.
Future plans include leveraging GCP's PaaS offerings (Dataproc, BigQuery) for even more elasticity and performance.
Migration Principles
1. Seamless Data Access for Users
IaaS prevented users from needing to modify their artifacts or services.
Cloud storage connector ensured HDFS compatibility.
They standardized HDFS clients to abstract the on-prem HDFS implementation specifics. The standardized HDFS client will be modified to translate the HDFS paths to Object store based paths via a “Path Translation Service.”
2. Enhanced Data Access Proxies
Abstracted the underlying compute clusters for Presto, Spark, and Hive.
3. Cloud-Agnostic Infrastructure
Uber's container environment and deployment tools were already built to be cloud-agnostic, making the expansion to GCP smoother.
4. Proactive Data Governance
Focused on supporting selected, approved GCP data services to avoid future complexities.